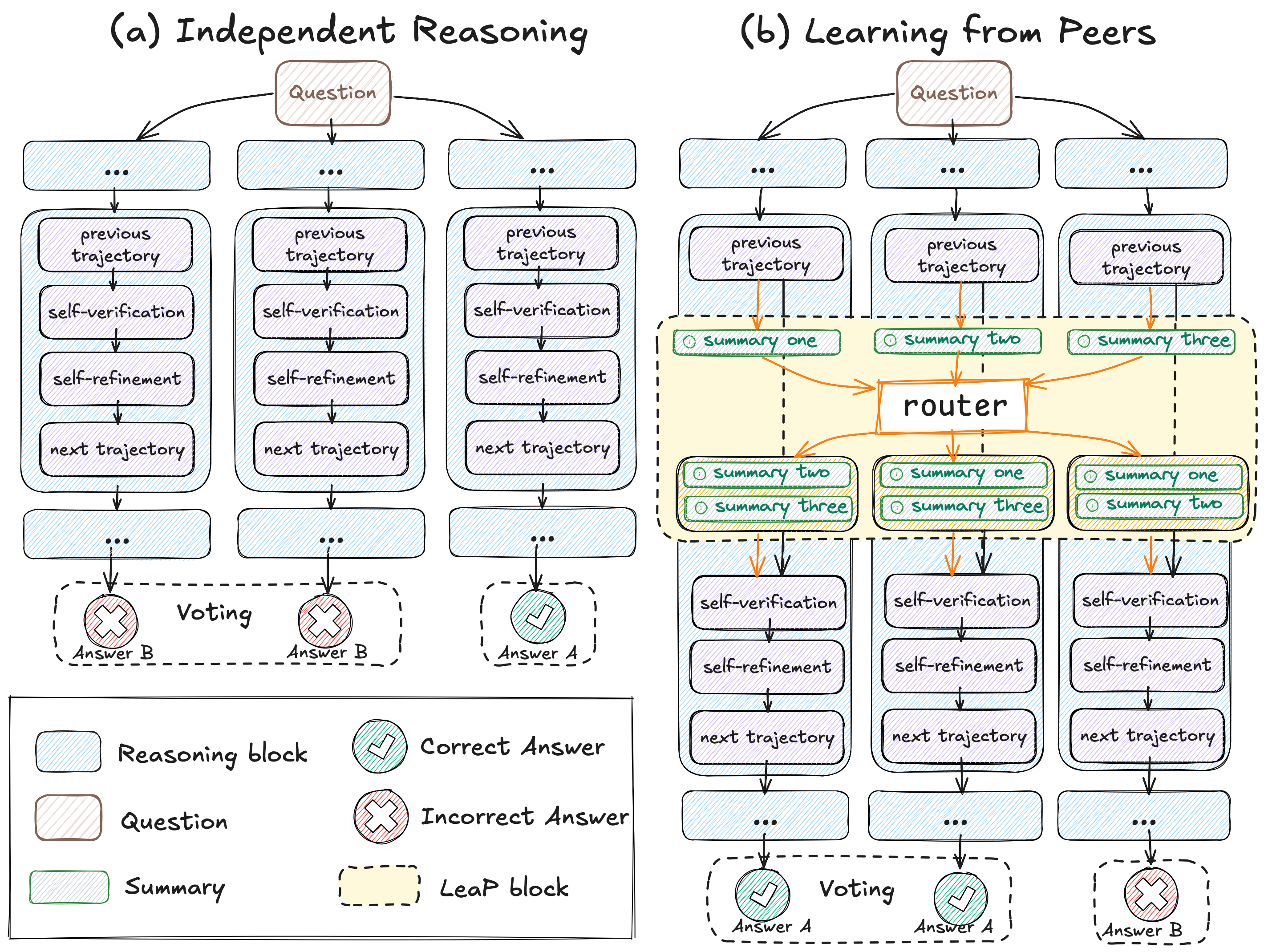
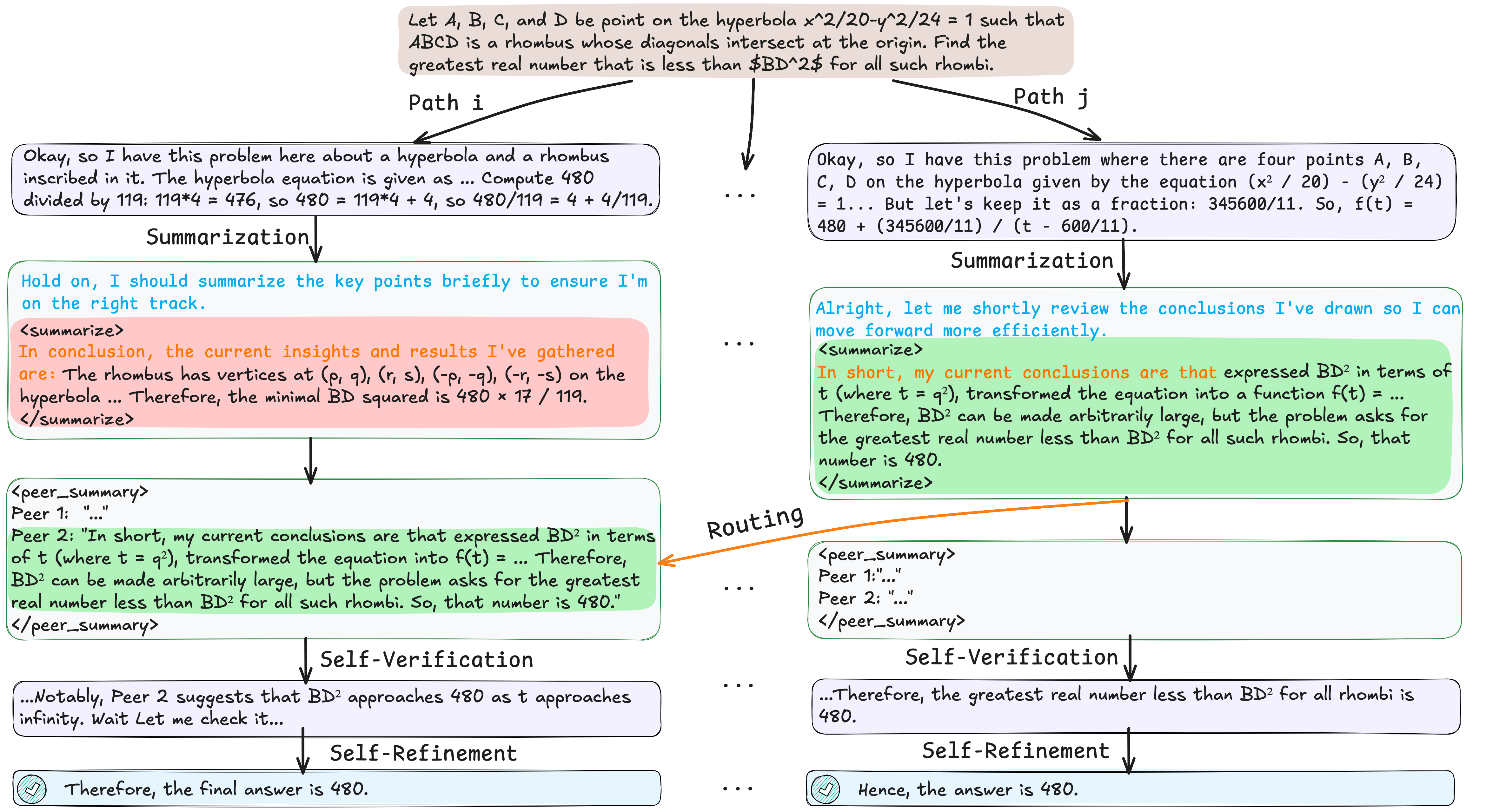
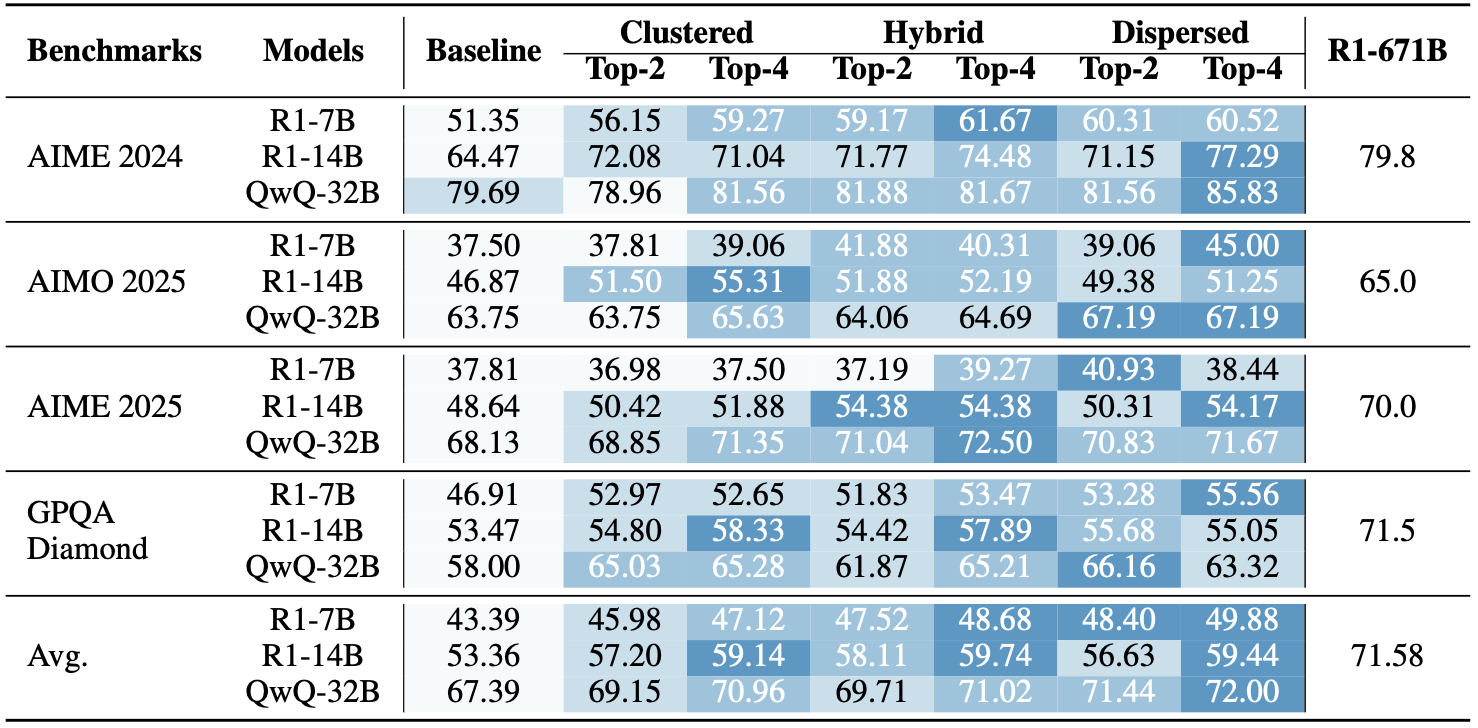
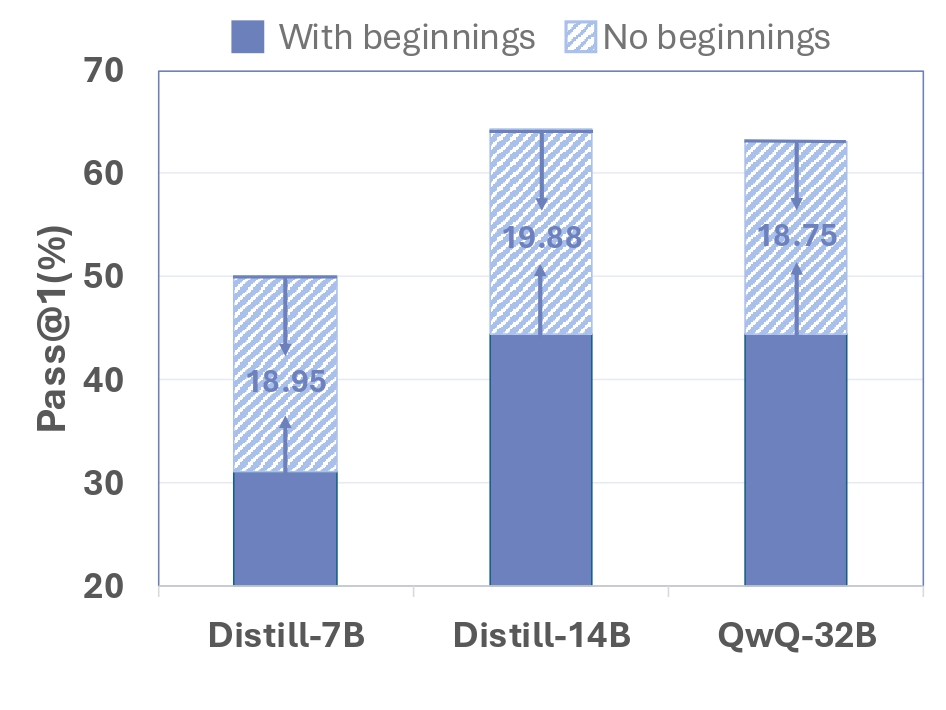
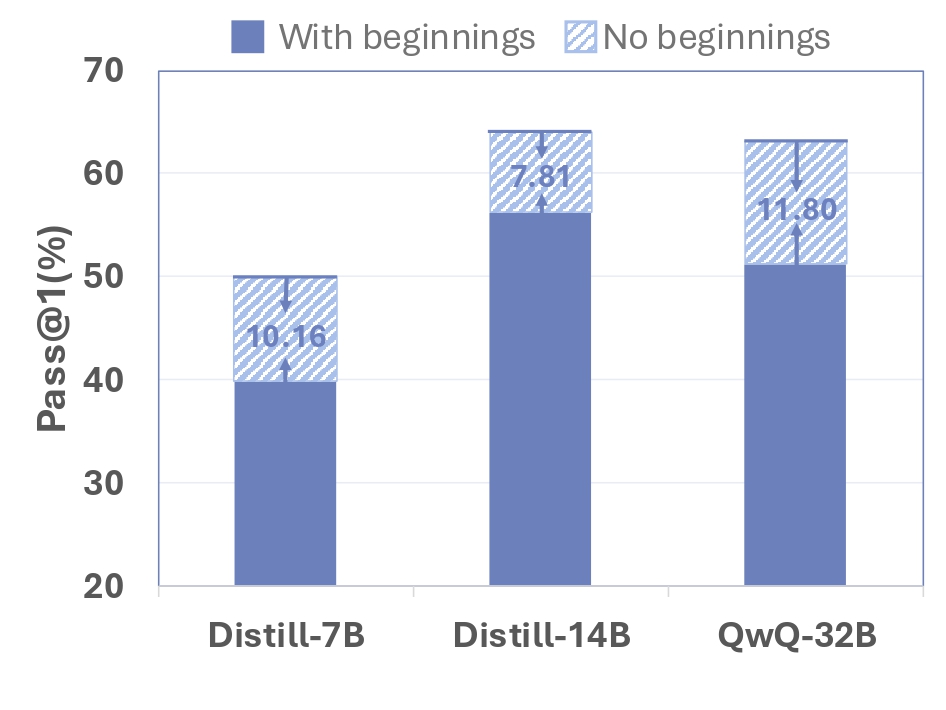
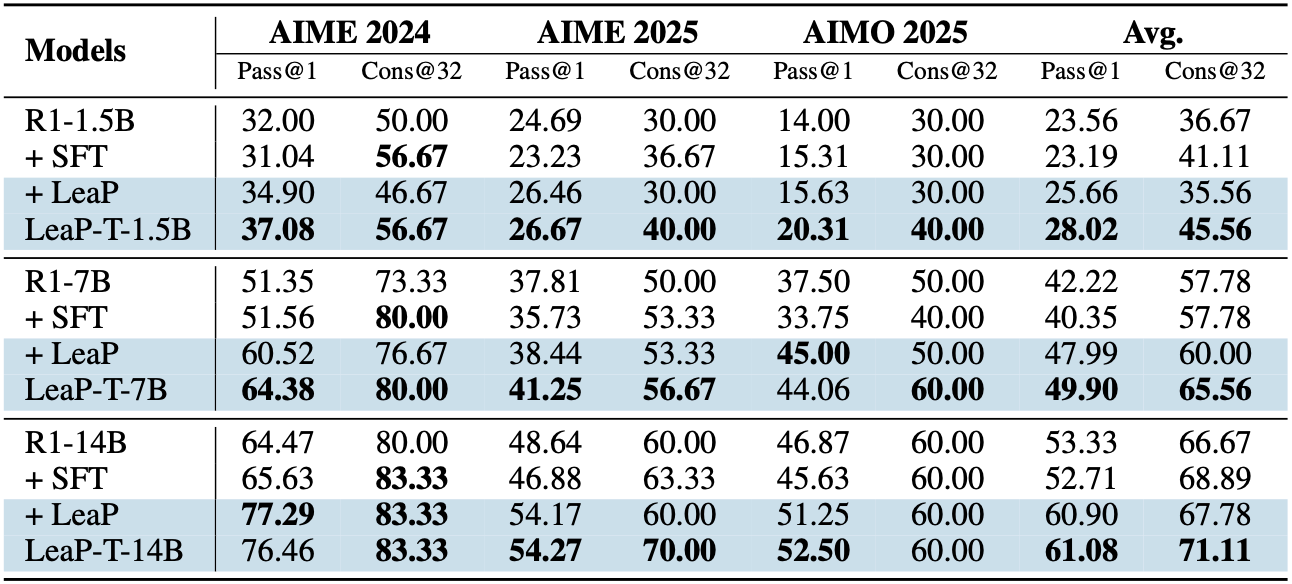


Learning from Peers in Reinforcement Learning: Integrating LeaP into RL frameworks could empower models to learn collaborative problem-solving strategies more effectively, potentially unlocking greater capabilities.
Learning from Peers with Different Expertise: Leveraging peers with specialized skills (e.g., some using web search, others using code execution) could significantly enhance reasoning quality, especially for multifaceted problems.